
Privacy and Energy-Aware Split Deep Learning in Edge Camera Network

Paper (This work is published in IEEE Transactions on Network and Service Management): https://ieeexplore.ieee.org/abstract/document/9941479
Motivation
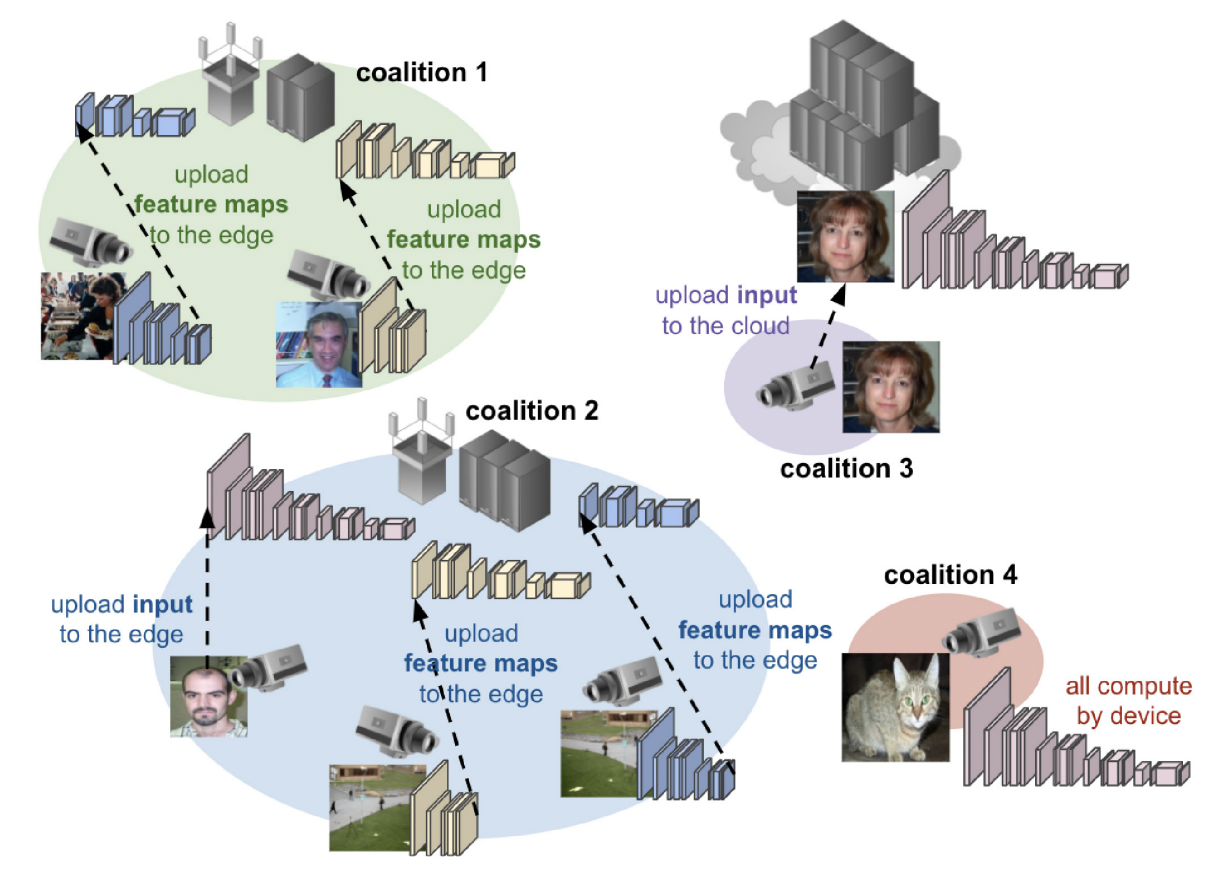
Recently, an increasing amount of application tasks have depended on deep learning (DL) inference models on Internet of Things (IoT) based camera networks. However, it is challenging to perform the inference of such resource-hungry DL models on the computationally limited IoT system. Compared to cloud computing, edge computing deploys resources near the end-users to reduce the transmission delay and retains the raw data on the trusted servers to mitigate privacy concerns. Since resources at the edge are limited, management like user association decisions, edge resources allocation, and device configuration with DL model parameter selection becomes essential.
Our approach
We proposes a coalition formation game-based algorithm to solve the association problem between IoT-based cameras and the edge nodes. Our goal is to maximize the social welfare that consists of multi-view detection enhancement, the privacy retained preference, and the power savings from the cameras. Besides, we adopt the concept of split-ML to provide more flexibility for networking and computing resources allocation at the edge.
An illustration of the association between IoT-based cameras and edge nodes.
Configuration table for edge cameras
The concept of Split-ML in Edge Camera Network is shown in the figure below. The inference of DNN models can be decomposed into two groups of consecutive layers according to the different output sizes of each layer. The former part (close to input) will be executed by local IoT-based camera while the latter part (close to output) will be performed by the associated edge server.
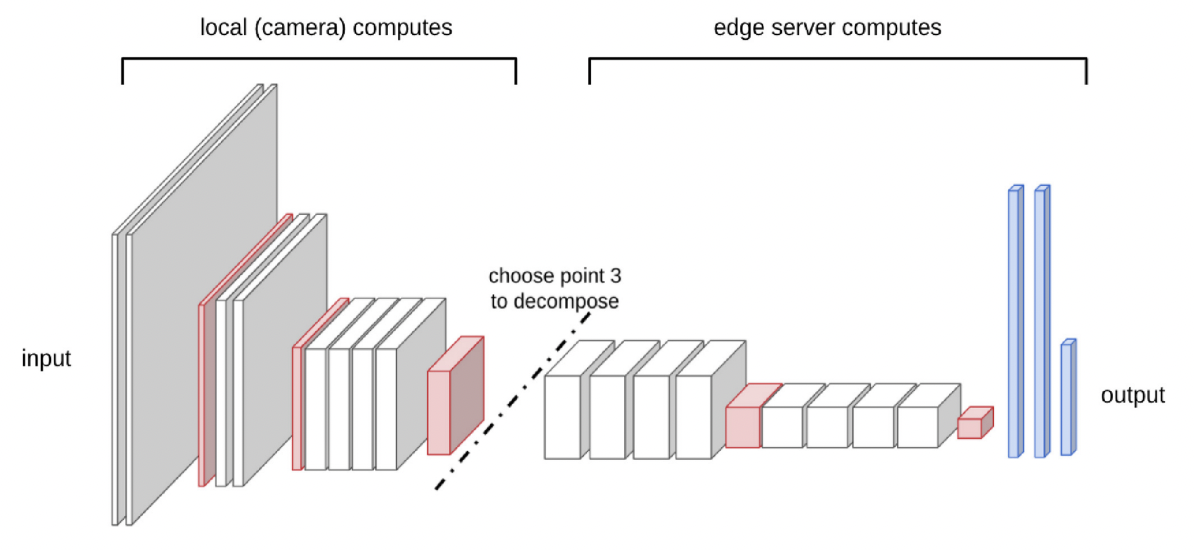
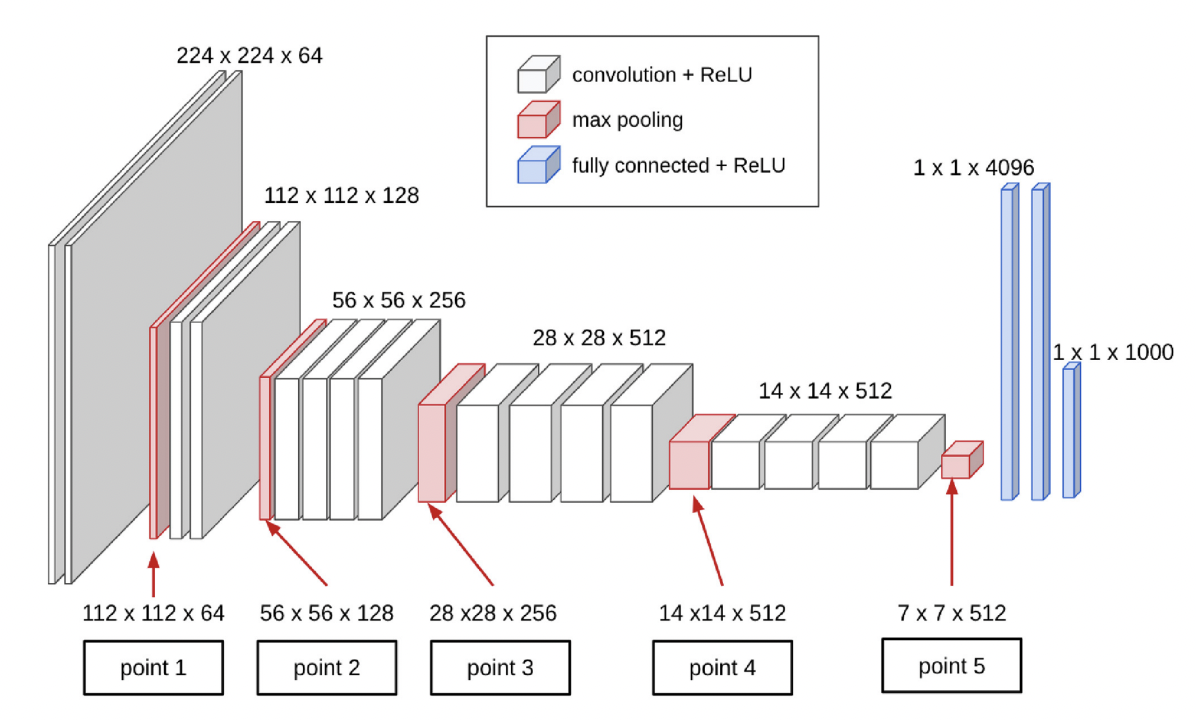
Different model and different input image resolution will result in different network architecture and hence different possible split points. The following figure shows an example of possible split points for VGG19. Different split points will correspond to different transmission requirement (in Mbps) from edge camera to edge server as well as different server computing requirement and camera computing requirements (in BFLOPs).
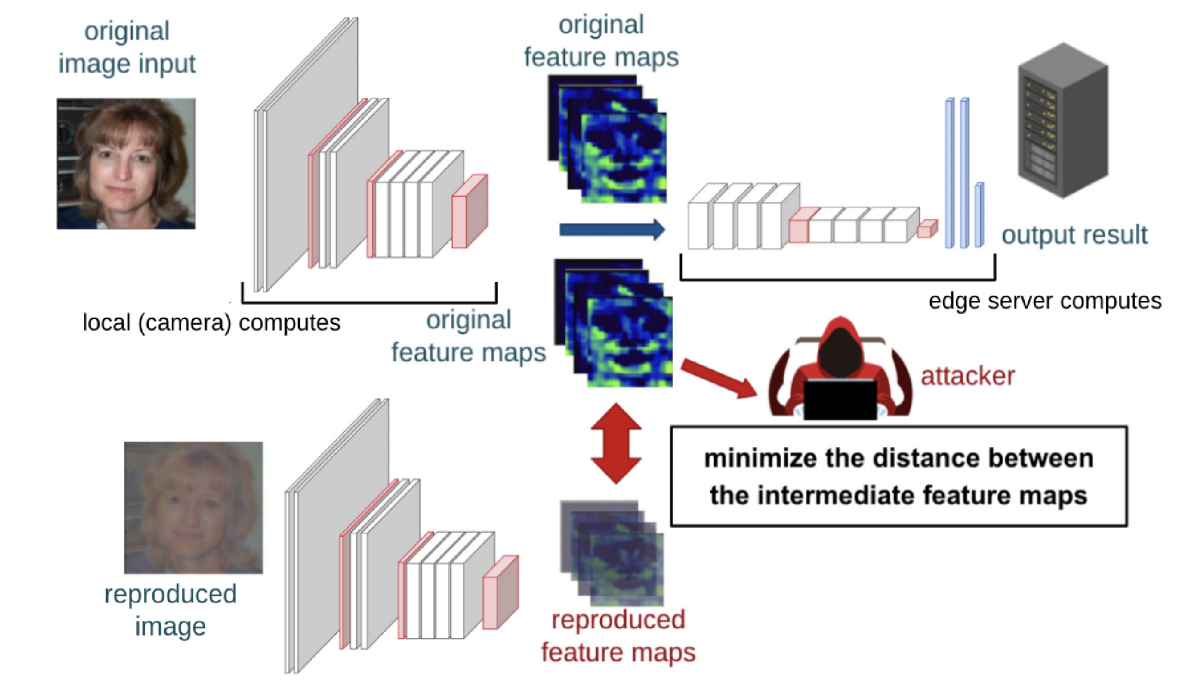
Privacy leakage issue when performing split
With DNN partition techniques, each partition point would correspond to the output of a certain layer, that is, the feature map after executing the former part of the model. Research has shown that attackers can still recover the original raw image to some degree from these feature maps (see the figure below).
An example of white-box regularized maximum likelihood estimation attack for VGG19 on Caltech101 dataset.
Moreover, feature maps from earlier layers are easier to reproduce, while those from later layers often require more effort to recover. The degree of recovery varies according to the split point selected. We use the structural similarity index measure (SSIM) as a metric to evaluate the quality of the reproduced images.
An illustration of images reproduced from intermediate feature maps of different split points.

It is worth noting that when splitting at an earlier layer of the deep learning model (the case in which the camera has less computation workload), the attackers need less effort to obtain an image similar to the original data. On the other hand, if the split point is close to the output side of the model (the case in which the camera needs to compute more), it is not easy for the attackers to get an image similar to the original data even if they spent more time on training the attack model. As can be seen from the description above, there is a trade-off between privacy leakage and the camera’s power consumption. Thus, it is necessary to select an appropriate configuration (split poin ) based on the camera’s computing capability and privacy preference.
Results
- The final coalition structure is proved to converge and maintain stability.
- The simulation results show that each design knob, including association decisions made by coalition formation, DNN layer-level partition, and multi-view detection, is essential under different scenario settings.
Some related research papers
Coalition formation games
- Han, Z., Niyato, D., Saad, W., Başar, T., & Hjørungnes, A. (2011). Game Theory in Wireless and Communication Networks: Theory, Models, and Applications. Cambridge: Cambridge University Press. doi:10.1017/CBO9780511895043
Model-level task decomposition
- Inference the models in the task pipeline on different computing devices
 From: Y. Zhang, J.-H. Liu, C.-Y. Wang, and H.-Y. Wei, “Decomposable intelligence on cloud-edge iot framework for live video analytics,”IEEE Internet of Things Journal, vol. 7, no. 9, pp. 8860–8873, 2020.
From: Y. Zhang, J.-H. Liu, C.-Y. Wang, and H.-Y. Wei, “Decomposable intelligence on cloud-edge iot framework for live video analytics,”IEEE Internet of Things Journal, vol. 7, no. 9, pp. 8860–8873, 2020.
Papers:
- C.-C. Hung, G. Ananthanarayanan, P. Bodik, L. Golubchik, M. Yu,P. Bahl, and M. Philipose, “Videoedge: Processing camera streams using hierarchical clusters,” in 2018 IEEE/ACM Symposium on Edge Computing (SEC), 2018, pp. 115–131.
- Y. Zhang, J.-H. Liu, C.-Y. Wang, and H.-Y. Wei, “Decomposable intelligence on cloud-edge iot framework for live video analytics,”IEEE Internet of Things Journal, vol. 7, no. 9, pp. 8860–8873, 2020.
Layer-level decomposition
- Run the inference of different layers in a single DL model on different computing devices
- Motivated by the difference of output data size between each DL layer → lead to different requirements of the networking resource
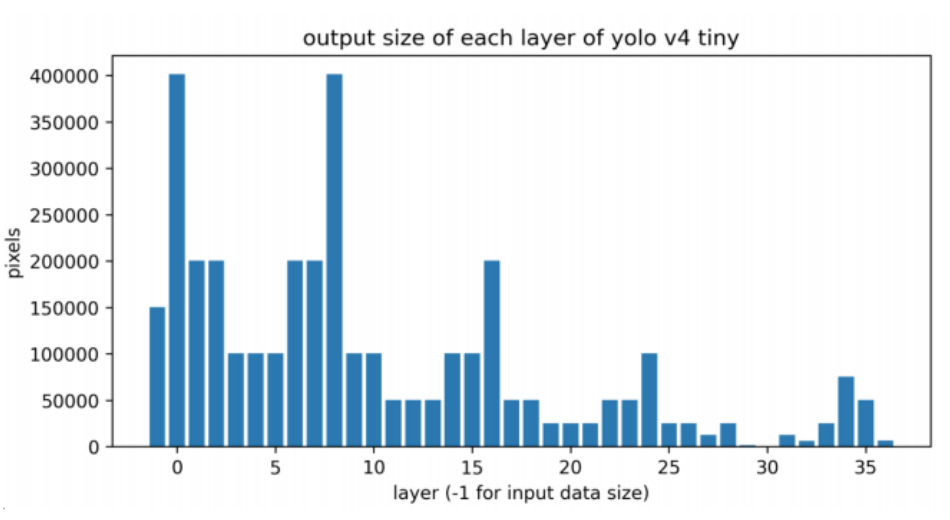
-
In the case of a single model with fixed variables, if the network situation and the capabilities of devices are known, we can find the best point for layer-level decomposition. Ex:
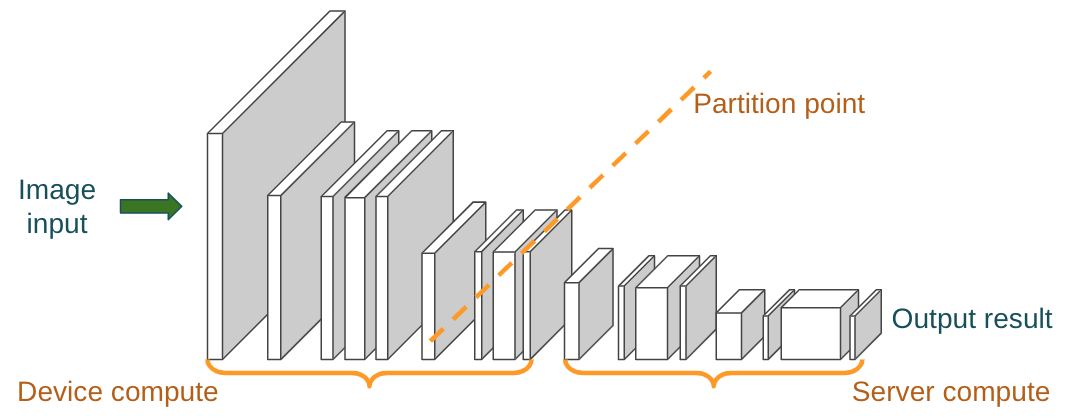
-
When the network situation is unknown, there may be multiple possible locations where partitions can be made, and if there are multiple kinds of tasks, multiple choices of models with different parameter settings that lead to different accuracy, it will be much more complicated
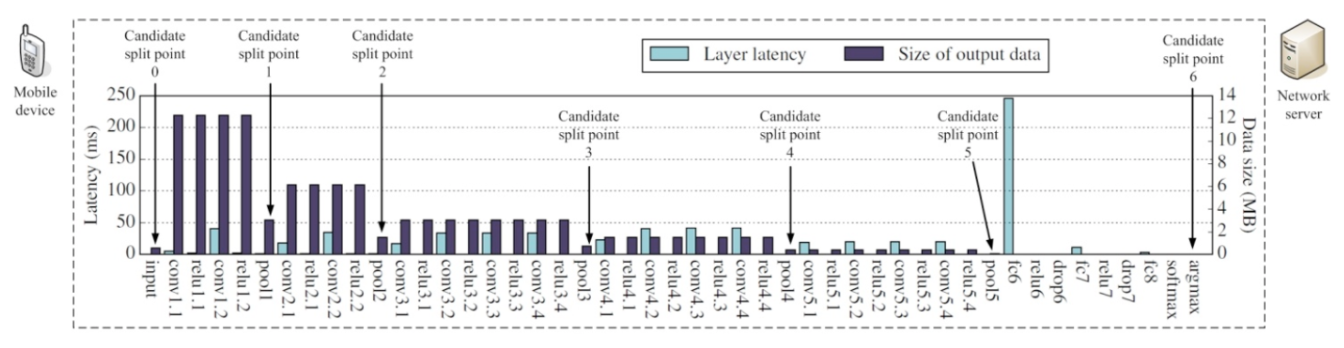 From: 3GPP, “5G System (5GS); Study on traffic characteristics and performance requirements for AI/ML model transfer,” 3rd Generation Partnership Project (3GPP), Technical Report (TR) 22.874
From: 3GPP, “5G System (5GS); Study on traffic characteristics and performance requirements for AI/ML model transfer,” 3rd Generation Partnership Project (3GPP), Technical Report (TR) 22.874
Papers
- J. Zhou, Y. Wang, K. Ota, and M. Dong, “Aaiot: Accelerating artificial intelligence in iot systems,”IEEE Wireless Communications Letters,vol. 8, no. 3, pp. 825–828, 2019.
- E. Li, L. Zeng, Z. Zhou, and X. Chen, “Edge ai: On-demand accelerating deep neural network inference via edge computing,”IEEE Transactionson Wireless Communications, vol. 19, pp. 447–457, 2020.
- L. Zeng, E. Li, Z. Zhou, and X. Chen, “Boomerang: On-demand cooperative deep neural network inference for edge intelligence on the industrial internet of things,”IEEE Network, vol. 33, no. 5, pp. 96–103,2019.
- C. Hu, W. Bao, D. Wang, and F. Liu, “Dynamic adaptive dnn surgery for inference acceleration on the edge,” in IEEE INFOCOM 2019 - IEEE Conference on Computer Communications, 2019, pp. 1423–1431.
Parallel decomposition
- parallel decomposition divides the input data frame into several patches and performs the inference computation in parallel on different devices.
Papers
- Z. Zhao, K. M. Barijough, and A. Gerstlauer, “Deepthings: Distributed adaptive deep learning inference on resource-constrained iot edge clusters,”IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems, vol. 37, no. 11, pp. 2348–2359, 2018.
- R. Hadidi, J. Cao, M. S. Ryoo, and H. Kim, “Toward collaborative inferencing of deep neural networks on internet-of-things devices,”IEEE Internet of Things Journal, vol. 7, no. 6, pp. 4950–4960, 2020.
- L. Zeng, X. Chen, Z. Zhou, L. Yang, and J. Zhang, “Coedge: Cooperative dnn inference with adaptive workload partitioning over heterogeneous edge devices,”IEEE/ACM Trans. Netw., vol. 29, no. 2, p. 595–608, apr2021. [Online]. Available: https://doi.org/10.1109/TNET.2020.3042320
Both parallel and layer-level
Papers
- T. Mohammed, C. Joe-Wong, R. Babbar, and M. D. Francesco, “Distributed inference acceleration with adaptive dnn partitioning and offloading,” in IEEE INFOCOM 2020 - IEEE Conference on ComputerCommunications, 2020, pp. 854–863.
- E. Kilcioglu, H. Mirghasemi, I. Stupia, and L. Vandendorpe, “An energy-efficient fine-grained deep neural network partitioning scheme for wireless collaborative fog computing,”IEEE Access, vol. 9, pp.79611–79627, 2021.